前言
人工智慧是一種基於「模型」的訓練運作的技術,分為判別式與生成式兩種。簡單來說,YOLO 是前者,能幫我們分類餵進去的資料;ChatGPT 是後者,能根據餵給它的資料來生出新東西。
主流的電腦視覺開發工具包括 OpenCV、MediaPipe 與 YOLO,OpenCV 有一套完整的影像處理功能,通常我們會將 OpenCV 視為一個框架,用來配合 MediaPipe 或 YOLO 進行開發。
MediaPipe 與 YOLO 都能做影像或骨架辨識,為何我選用 YOLO 而不是 MediaPipe 呢?因為 MediaPipe 在 Windows 上不支援 GPU 運算 (CPU 算得慢 / GPU 快很多),而 YOLO 可以。所以為了能用學校實驗室的電腦來快速開發,就決定現行先以 YOLO 為主。
在這邊,我會用 Windows 11 + NVIDIA RTX 顯示卡的環境來示範 Python 開發環境的建立,以下為官方建議的系統規格:
- Python 3.8 或以上版本
- NVIDIA 顯示卡與 CUDA 11.2 或以上版本
我的規格是:
- Python 3.10
- NVIDIA RTX 4060
- CUDA 12.4 (版本錯誤沒關係,我會教你怎麼重新安裝)
我們預計要使用 VS Code 來做 YOLO 的開發,今天會帶大家經歷以下流程:
- 建立 VS Code 基本環境
- 使用 Scoop 安裝 Python 3.10
- 建立 Python 虛擬環境
- 安裝 CUDA 12.4
- 安裝 PyTorch、YOLO 與測試 (確認能使用顯示卡來加速運算)
說明就到這裡,接下來將進入主題:
建立 VS Code 基本環境
VS Code 是目前主流的程式碼編輯器,我們可以安裝各種擴充功能,來讓它變成中文介面和支援 Python 的開發。
首要步驟是新開一個資料夾,並按住 Shift 再點擊滑鼠右鍵,選擇「以 Code 開啟」。
開啟 VS Code 後,先建立一個名為 main.py 的新檔案,再切換到擴充功能,安裝中文語言包、Pylance、Python 與 Python Debugger。
使用 Scoop 安裝 Python 3.10
這裡先預設大家的電腦還沒安裝任何版本的 Python,我們接下來會使用 Scoop 套件管理器來安裝 Python 3.10,讓工具來幫你處理麻煩的系統環境設定。
首先,從頂部選單開啟:終端機 > 新增終端。
複製並貼上以下指令,等待完成 Scoop 的安裝。
1Set-ExecutionPolicy -ExecutionPolicy RemoteSigned -Scope CurrentUser
2Invoke-RestMethod -Uri https://get.scoop.sh | Invoke-Expression
Scoop 安裝好後,下一步要來安裝 Python,請複製並貼上以下指令,等待 Python 3.10 完成安裝。
1scoop bucket add versions
2scoop install versions/python310
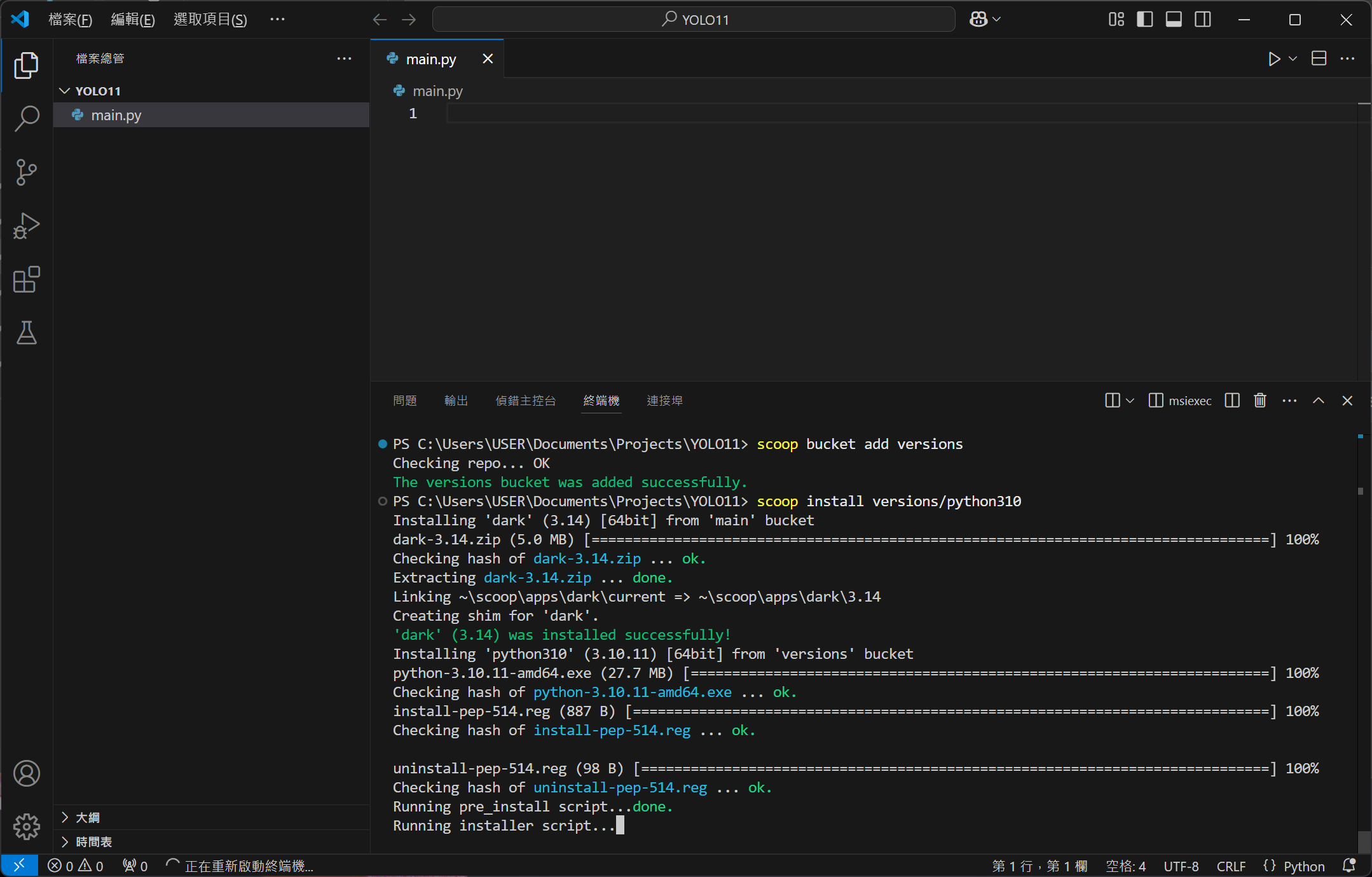
建立 Python 虛擬環境
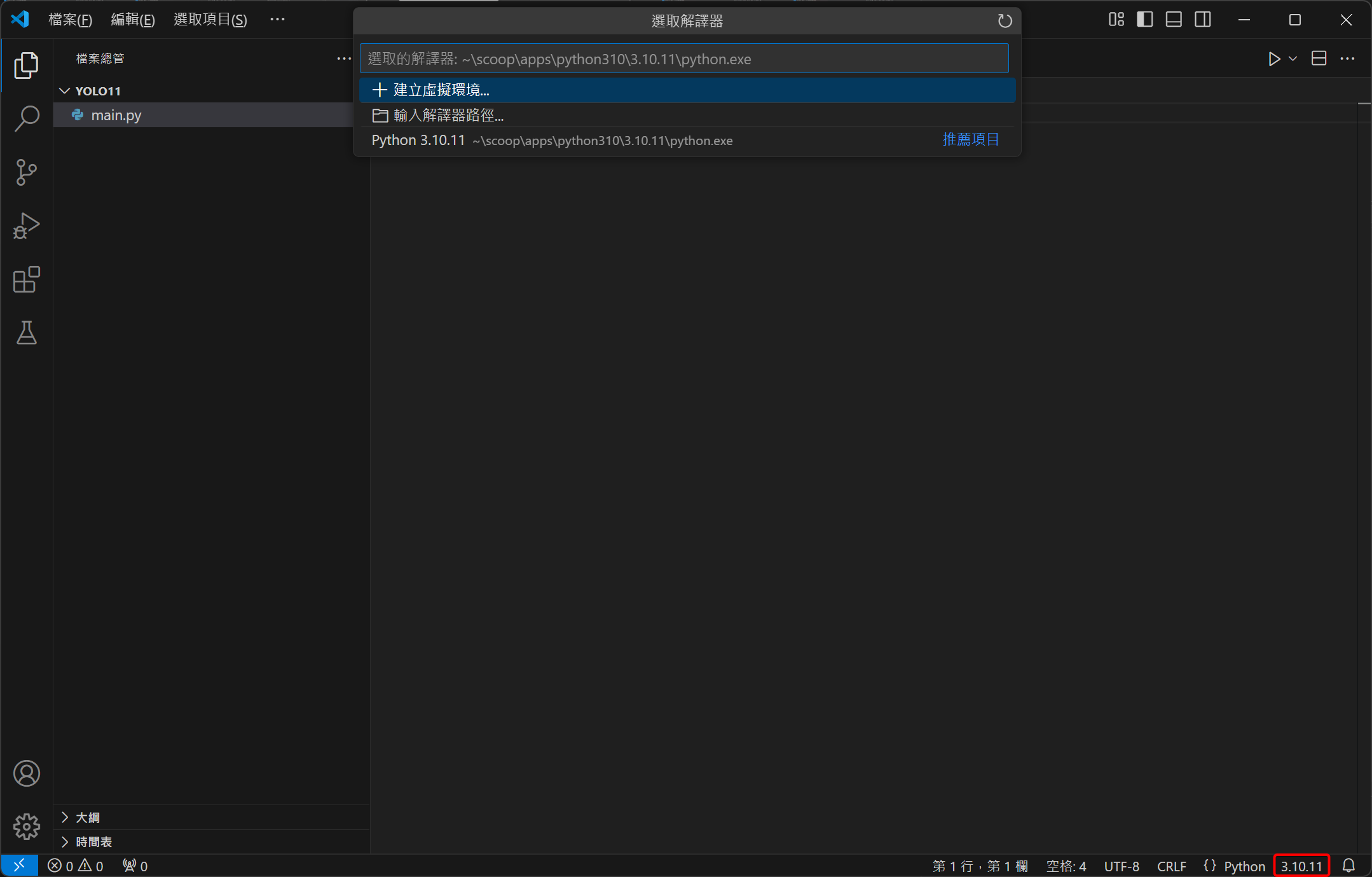
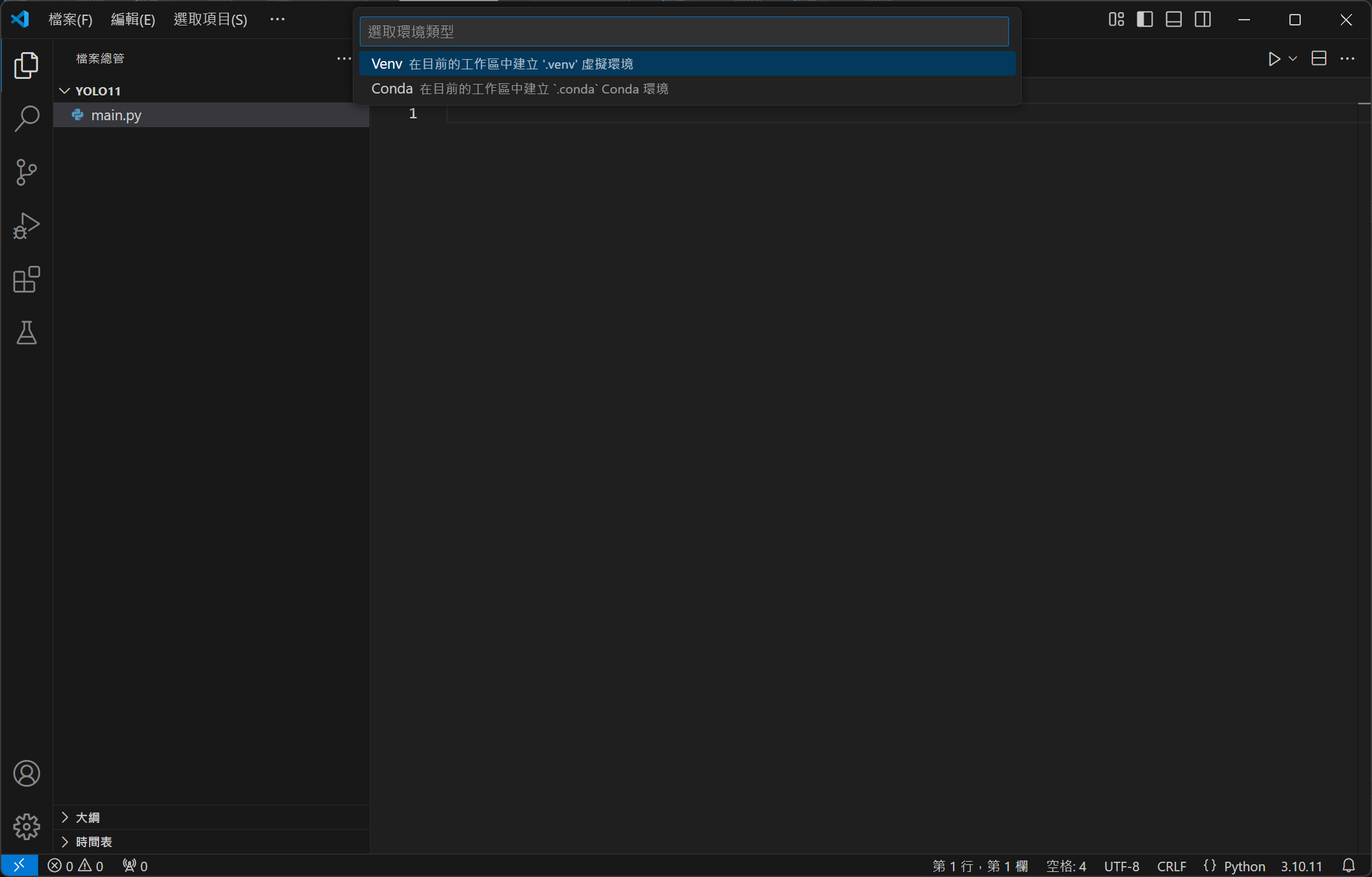
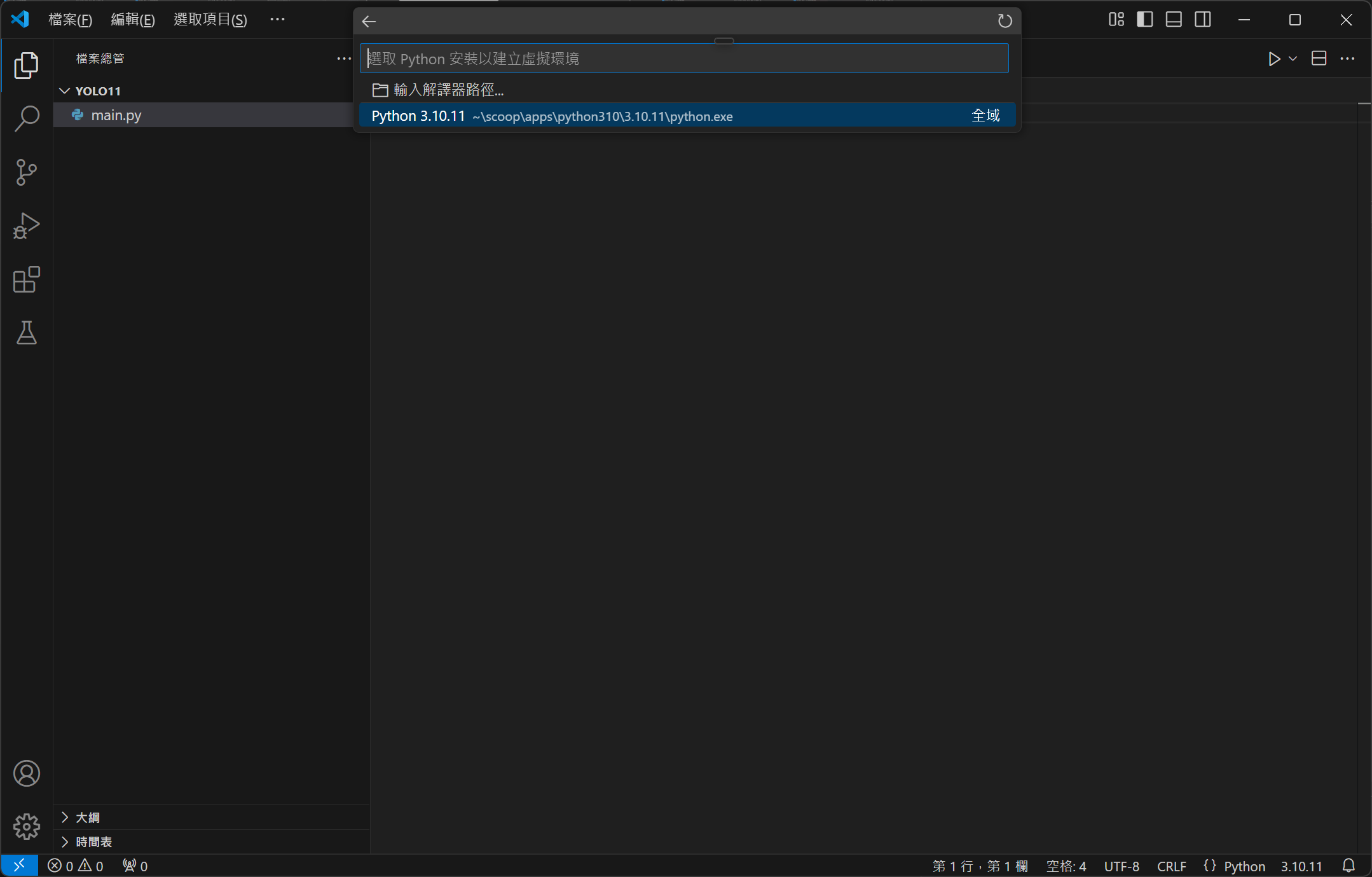
現在請將 VS Code 全部關閉再重新啟動,這時開啟 main.py 時,視窗右下角應該會出現 3.10.11 的版本號碼,請點擊它,並依序選擇「建立虛擬環境」、「Venv」、「Python 3.10.11」。
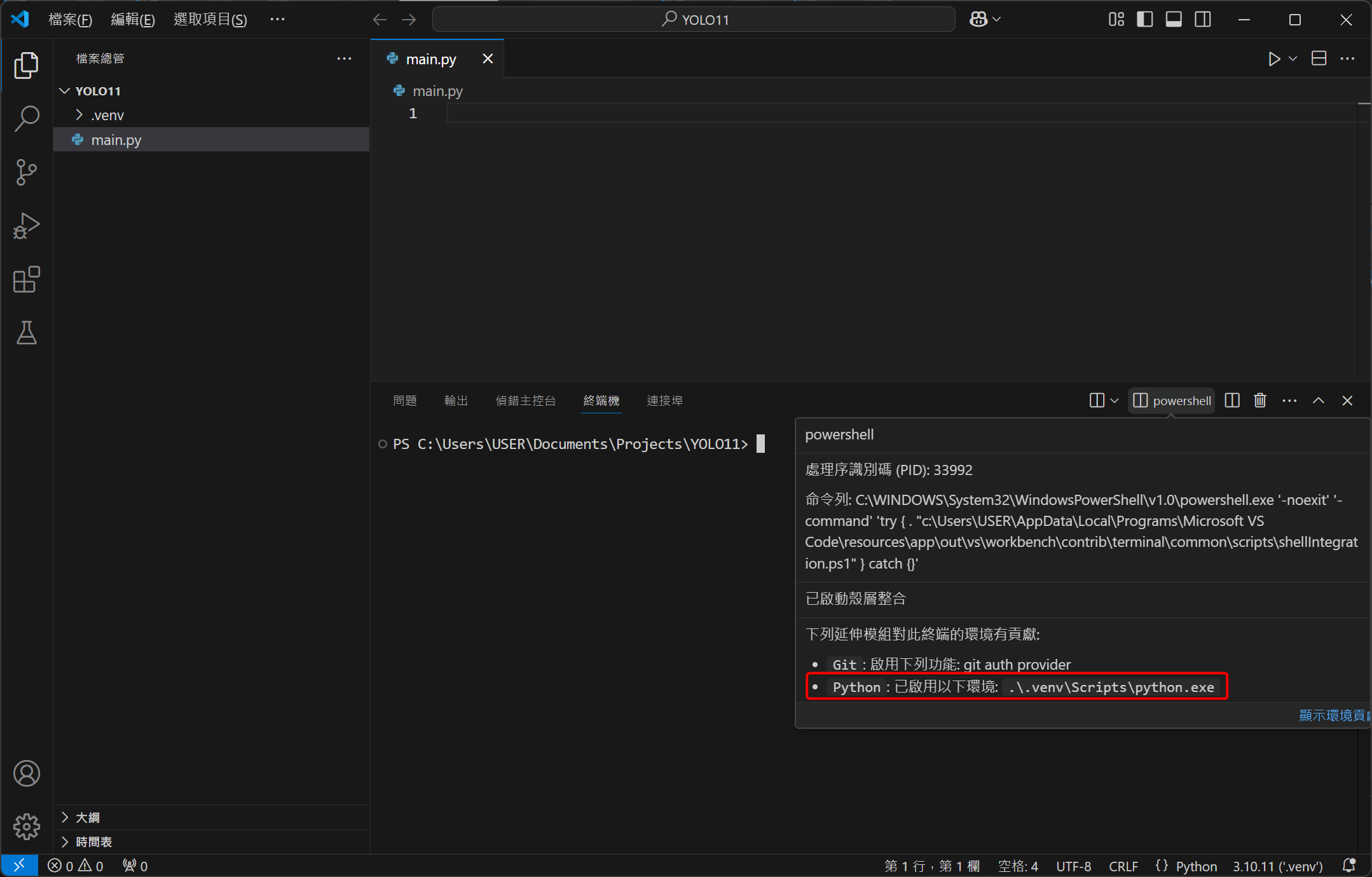
最後再次開啟終端機,滑鼠放在終端機面板右上角的 powershell 上,確認有成功套用虛擬環境 (紅框處)。
安裝 CUDA 12.4
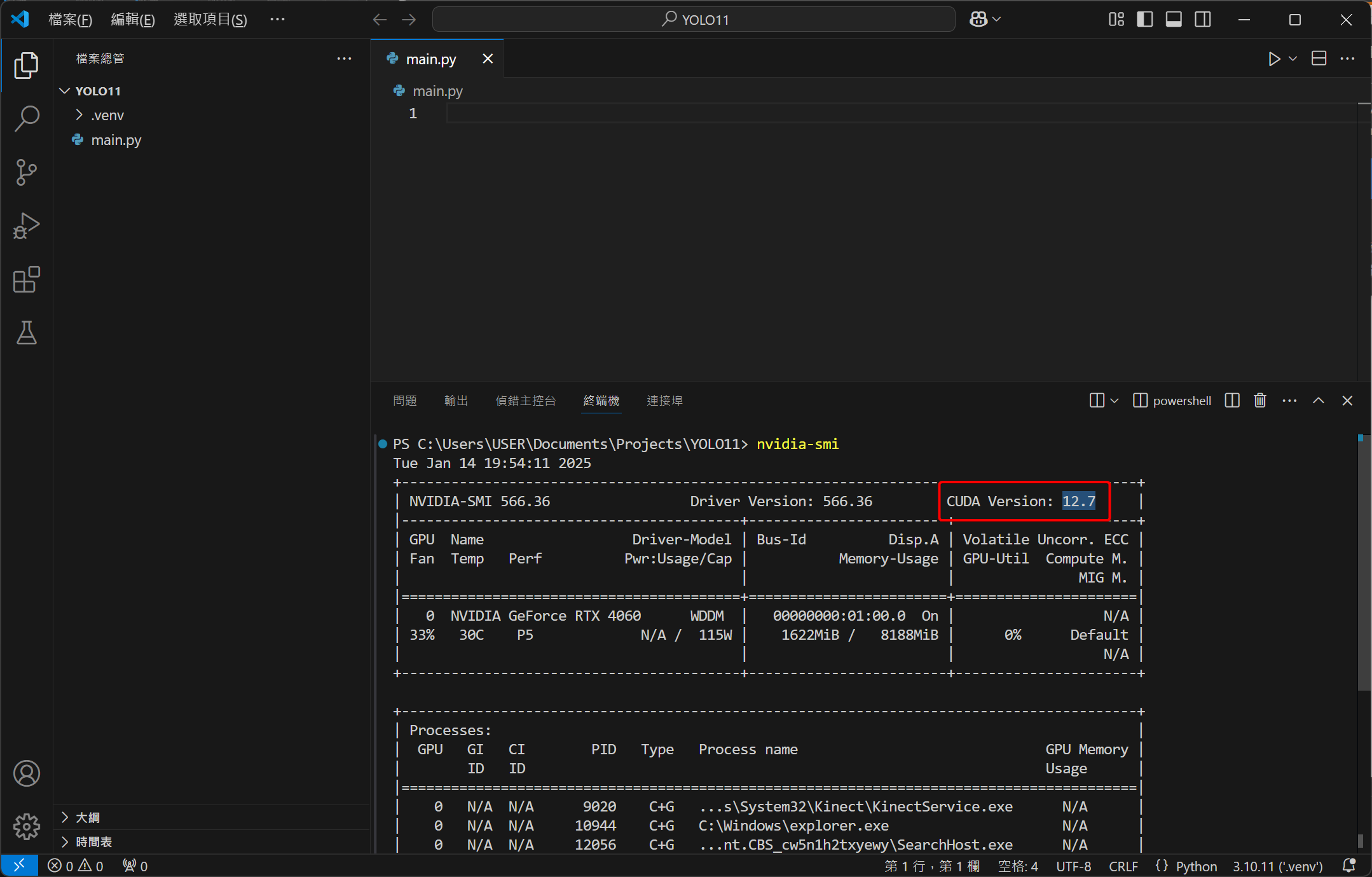
接下來要處理顯示卡的 CUDA 支援,我們沿用剛才開的終端機,嘗試輸入以下指令:
1nvidia-smi
你可能會遇到幾種結果:
- 找不到指令
- 有顯示東西,但它的版本不是 11.8、12.1 或 12.4
如果你顯示的 CUDA 版本是 11.8、12.1 或 12.4,那恭喜你,這一節可以全部跳過,直接進到安裝 PyTorch、YOLO 與測試,其它結果則跟著我繼續往下做 (我遇到的是版本錯誤)。
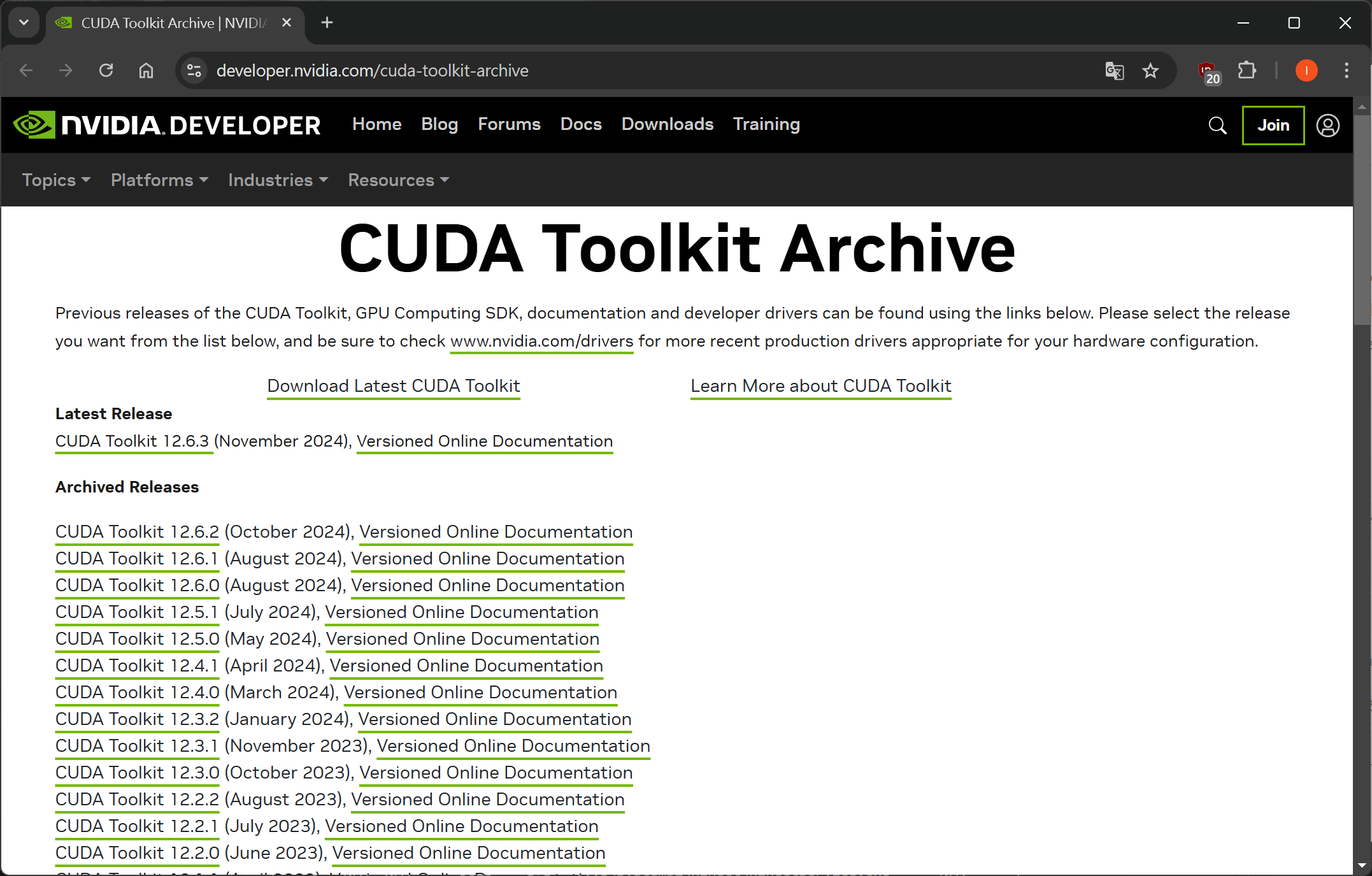
首先,前往 CUDA Toolkit Archive,選擇 11.8、12.1 或 12.4 開頭版本的 CUDA Toolkit 來下載 (建議裝 12.4.1)。
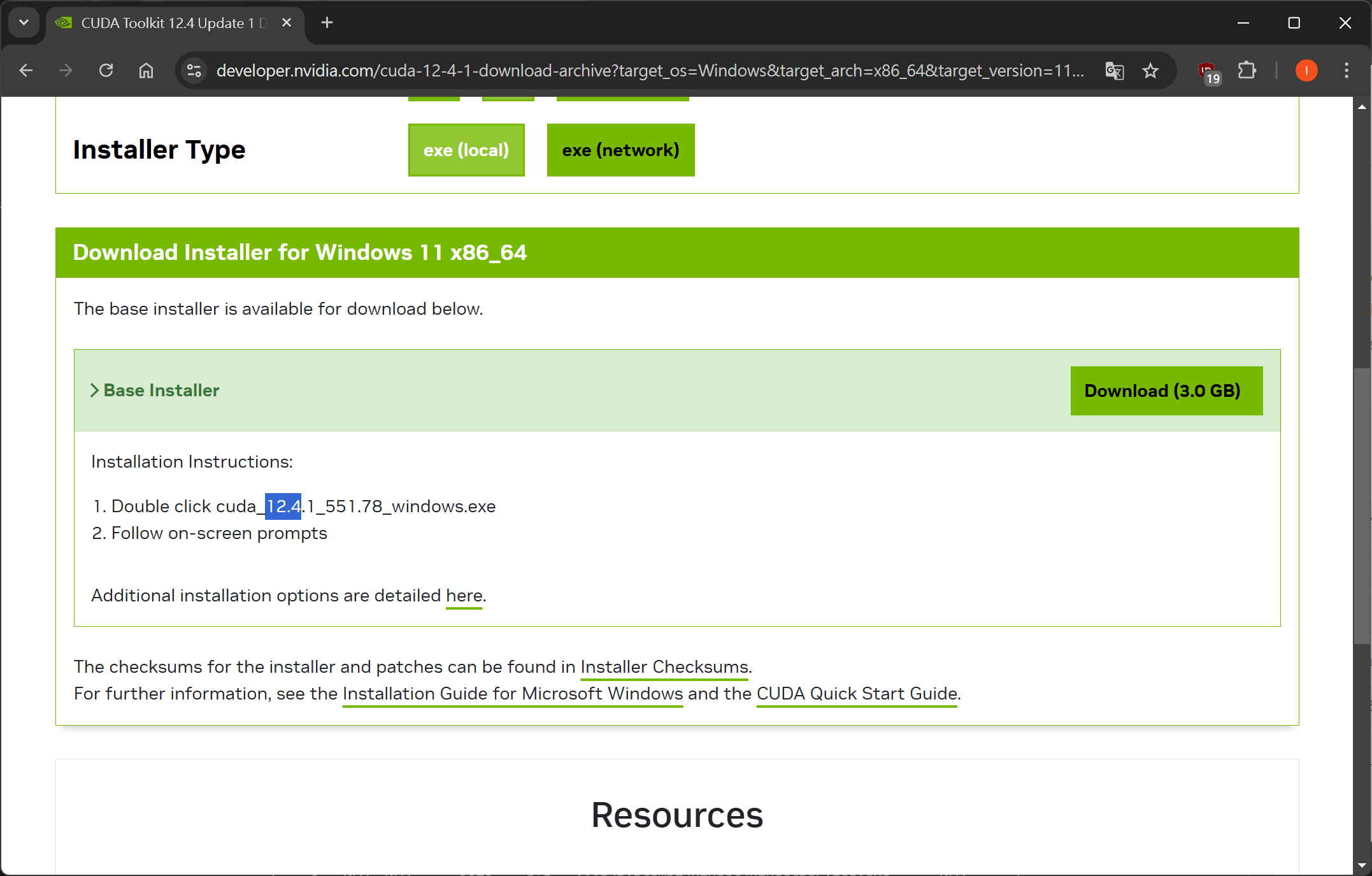
以我的電腦規格來說,電腦規格會依序選擇「Windows」、「x86_64」、「11」與「exe (local)」,最後點擊 Download 來下載。
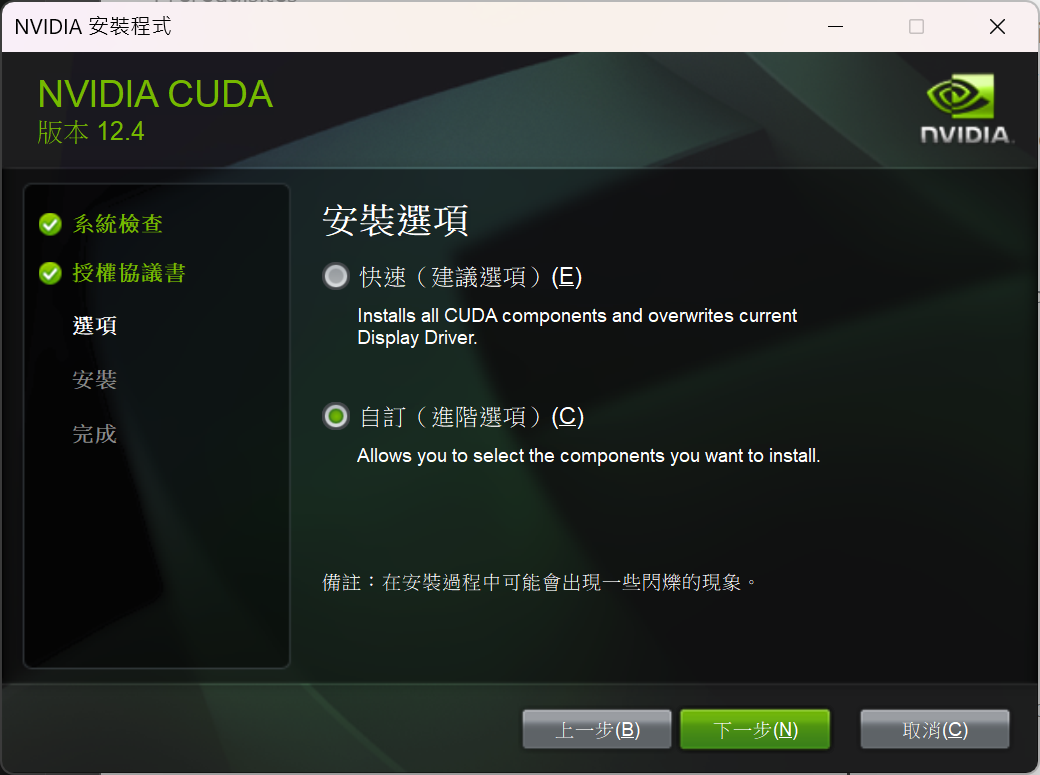
下載完成後直接啟動安裝程式,其中在選擇安裝選項時請選擇「自訂」,並取消勾選除了 CUDA 以外的選項。因為通常電腦都會自動幫你安裝顯示卡驅動,但如果你還沒裝驅動,則可以保留選項的勾選狀態。
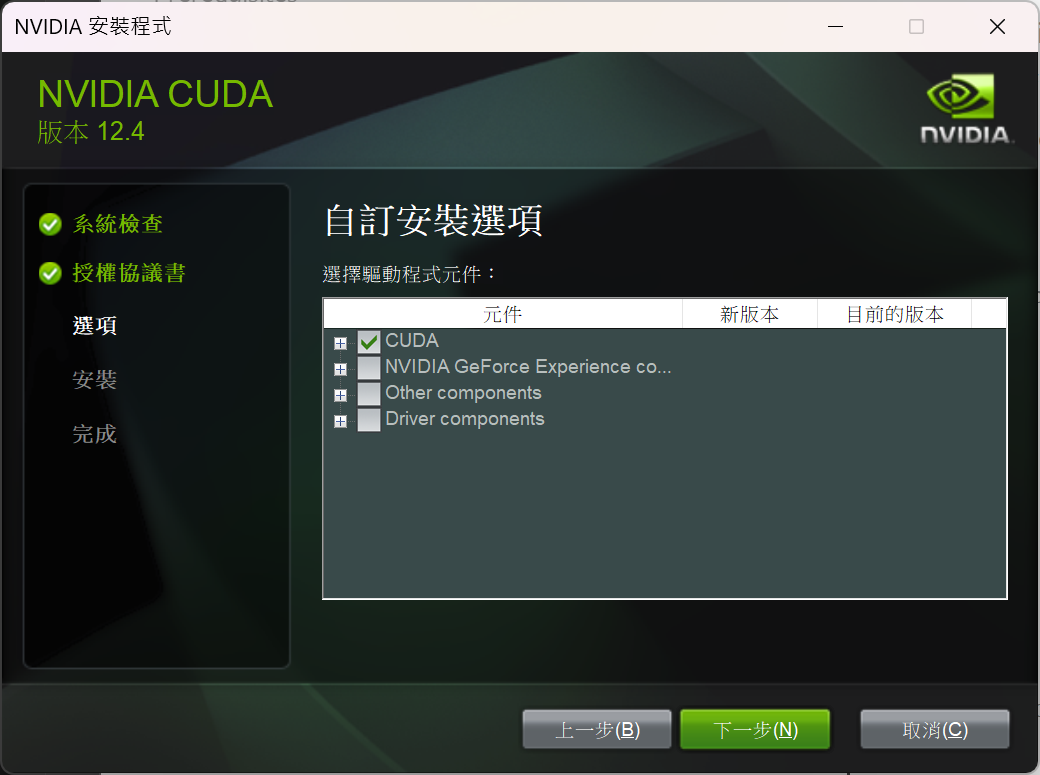
安裝 PyTorch、YOLO 與測試
到這個環節,你電腦的 VS Code、Python 和 CUDA 應該都已經安裝並設定好了,現在我們要先來安裝 YOLO 依賴的 AI 框架「PyTorch」。
首先,繼續沿用先前開的終端機,複製並貼上以下指令,安裝最新正式版且支援 CUDA 12.4 的 PyTorch:
1pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu124
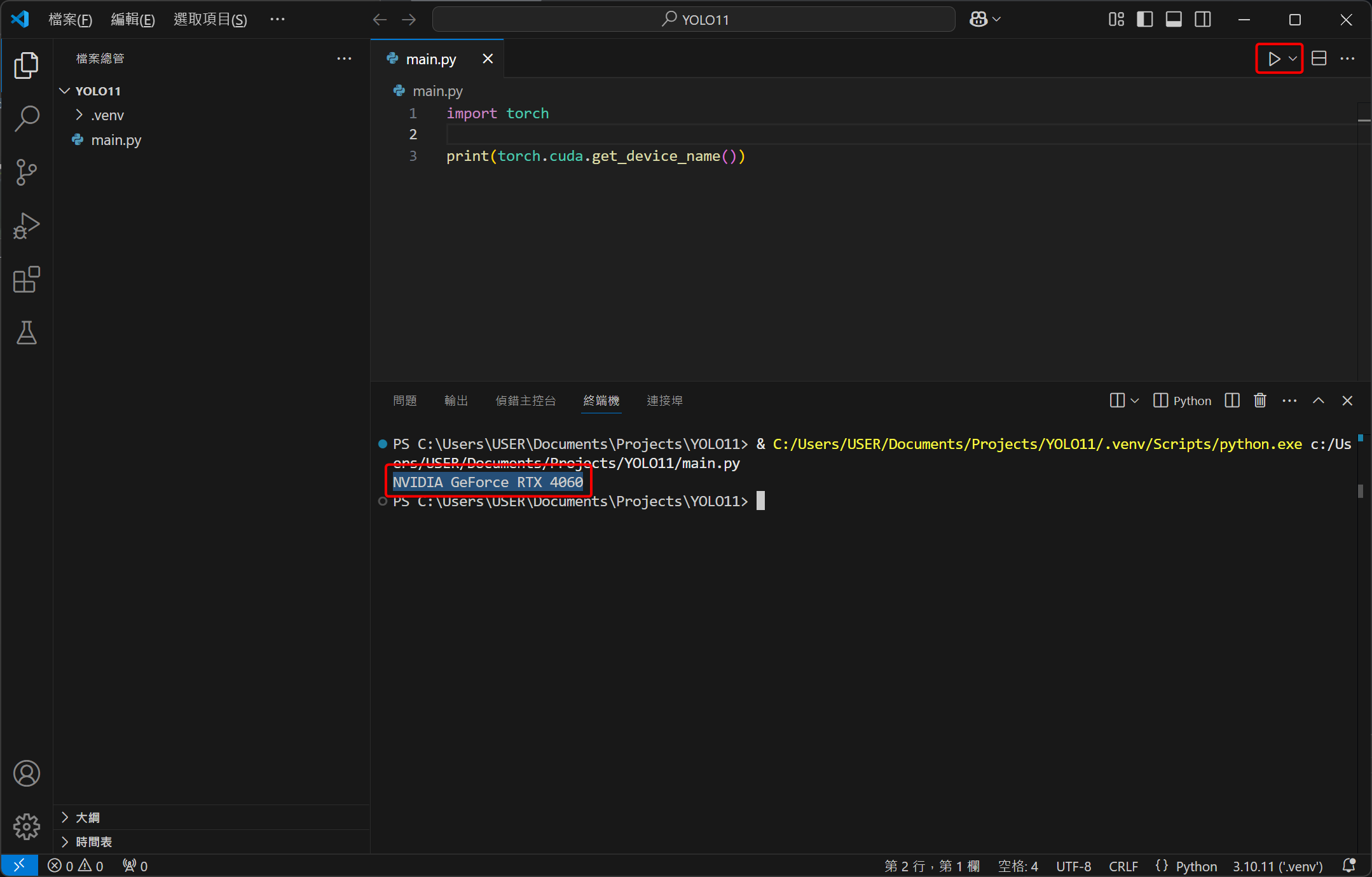
接下來寫一段程式碼來測試 PyTorch 有沒有成功抓到顯示卡的 CUDA:
1import torch
2
3print(torch.cuda.get_device_name())
點擊右上角執行後 (紅框處),應該會出現 NVIDIA GeForce XXXX 的字眼,例如我的就是 RTX 4060,代表有成功抓到,PyTorch 可以用 CUDA 來加速運算。
當 PyTorch 的 CUDA 可以正常運作後,我們就能來安裝 YOLO,請輸入以下指令進行安裝:
1pip install ultralytics
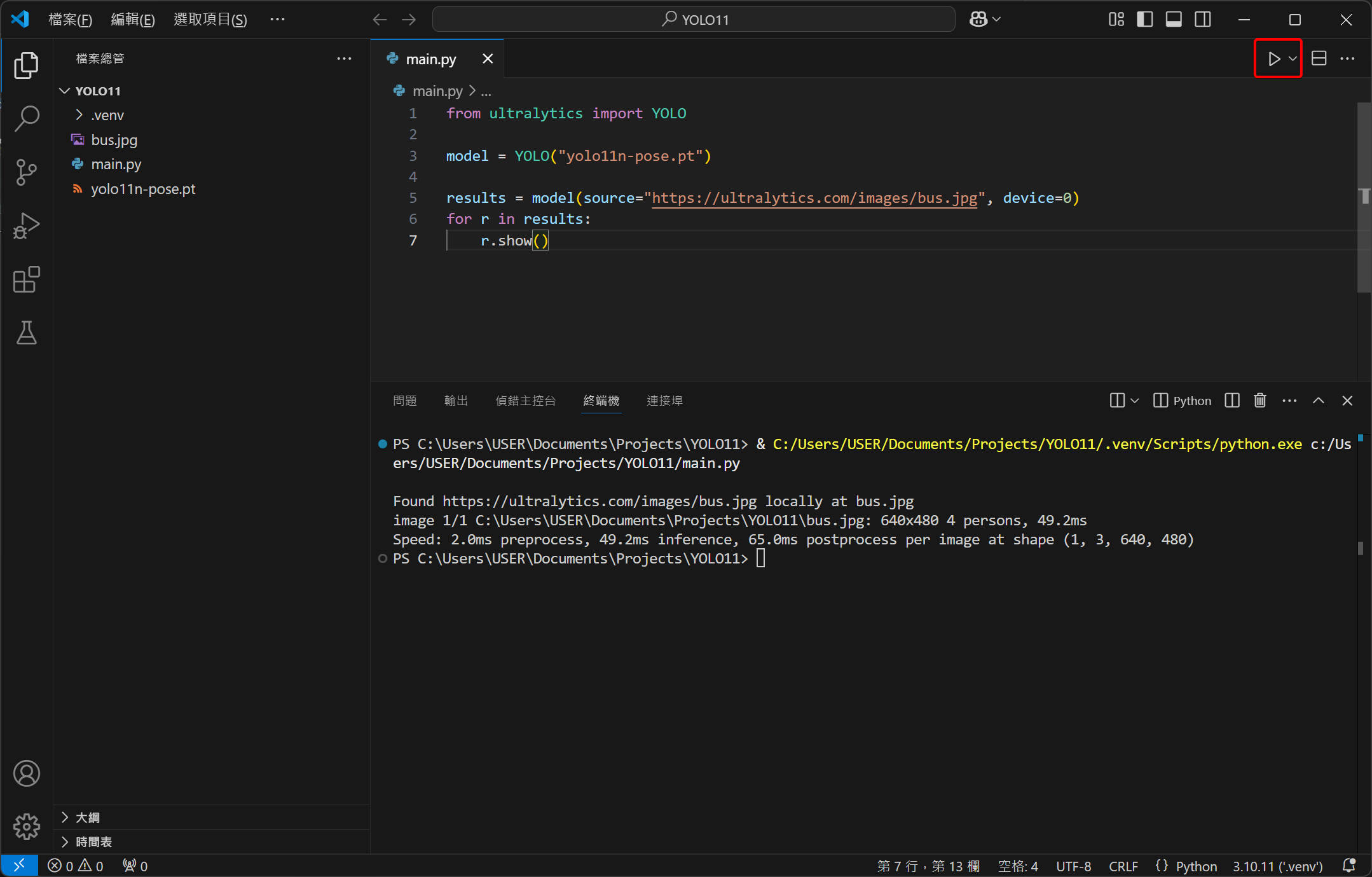
最後請複製貼上以下程式碼,這邊我們用 YOLO 的 YOLO11n-pose 模型來辨識影像中的人物骨架,其中使用 device=0 參數來確保 YOLO 有用顯示卡來算,並用 show() 來將結果顯示出來。
1from ultralytics import YOLO
2
3model = YOLO("yolo11n-pose.pt")
4
5results = model(source="https://ultralytics.com/images/bus.jpg", device=0)
6for r in results:
7 r.show()
一樣點擊右上角按鈕來執行,最後會跳出一張圖片,裡面所有的人物應該都會被框起來,骨架也會被標出來,YOLO 已能順利運作!
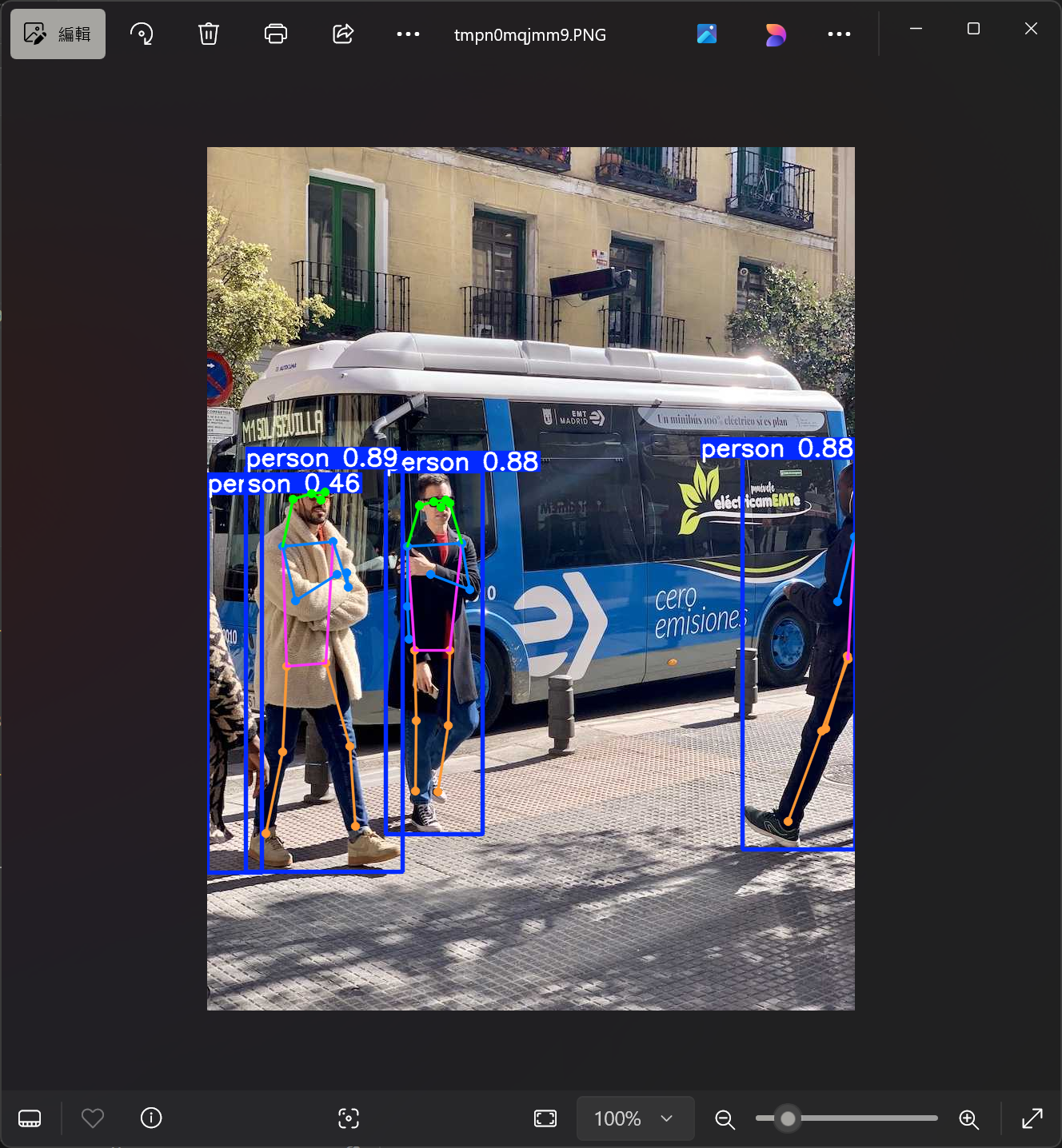
今天教學就到這邊,我們現在應該都已經成功建立 YOLO 的開發環境,現在我們只有做出簡單的人體骨架辨識,未來將會試著將它連接到網路攝影機 (WebCam) 上,即時擷取我們的肢體狀態,再透過網路來輸出座標到 Unity 或其它程式或工具中!
有遇到問題或有相關技術想要分享的歡迎在下方討論區留言,我會抽空回覆!